- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
What is data annotation?
Data annotation is a detailed and careful procedure of labelling or tagging different types of records. It aims to enrich them with meaningful indicators that serve as essential landmarks for various computational systems engaged in data processing and analysis. Annotation plays a vital role in closing the distance between raw data and the effective training of machine learning models, facilitating their ability to recognise patterns and make informed predictions.
In today’s increasingly digital times, data has become one of the most critical assets for diverse organisations, regardless of their size, industry, location, or scope of operations. Modern businesses can gain a competitive edge, drive efficiencies, boost strategic planning and unlock new opportunities for growth and development by leveraging data. Provided, next to its collection and storage, data is processed appropriately and securely and ultimately transformed into valuable insights that navigate human decision-making in the right direction.

The potential of data is immense and continually expanding, as highlighted in various studies. According to Statista, global data generation, copying, and utilisation were projected to reach 64.2 zettabytes in 2020 (to clarify: one zettabyte is a billion terabytes or a trillion gigabytes). To put this into perspective, Statista predicts that by 2025, this figure will skyrocket, surpassing 180 zettabytes. In this context, it is also crucial to bring attention to the substantial activity in social media, where an evident trend of spreading user-generated content is present, contributing significantly to the continuous collection of diverse data forms, including images, video, audio, and text. For instance:
The above examples clearly illustrate the growing shift towards a data-driven world. However, possessing more input does not necessarily translate to better outcomes, as suggested by Forrester Consulting. One of the company’s reports highlights that between 60 and 73% of all records gathered within an enterprise are never used for analytical purposes. This poses a critical challenge for businesses: implementing effective strategies for leveraging data, empowering success and revenue growth. Data annotation emerges as one of the key methodologies in this pursuit, enhancing the value of data by making it more applicable and actionable for analytical purposes.
What is the purpose of data annotation?
Data annotation is a crucial milestone in the machine learning pipeline, bolstering the capacity of AI models to undergo effective training, enhance performance, and elevate the quality and precision of the generated insights based on subsequent uploads of new and unseen data. This refers to the nuances of content, context, and significance embedded within text, audio, image, or video data.
In machine learning and artificial intelligence, the supervision involved in data annotation is indispensable. It encompasses overseeing the categorisation of collected records, marking them with contextual information such as category, type, specificity, or group, and providing labelled examples. This hands-on approach offers invaluable guidance for computational systems during training, empowering them to adapt and perform accurately and efficiently in real-world scenarios. Whether it applies to image recognition, natural language processing, sentiment analysis, or other complex tasks, data annotation is pivotal in enhancing the proficiency of machine learning models across diverse applications.
It is also worth emphasising that data annotation is a multifaceted process that extends beyond the immediate needs of training machine learning models. As technology advances, annotation is gaining importance, shaping how AI develops and influences various applications and areas. For instance:
- Customising Models for Specific Tasks: Data annotation caters to machine learning models for specific purposes, such as analysing player behaviour within a game regarding different playing styles, preferences, or skill levels. Another example involves relying on annotation to categorise social media user preferences, interests, or engagement patterns.
- Facilitating Research and Innovation: Annotated datasets are valuable resources for researchers and developers working on advancing AI technologies. They provide standardised benchmarks for evaluating and comparing the performance of different models, fostering collaboration and driving progress in artificial intelligence.
- Ensuring Ethical AI: Properly annotated data is essential to train fair and unbiased models, preventing biases from affecting predictions. This helps ensure AI systems treat everyone fairly and without discrimination.
Why is data annotation important in Trust and Safety?
With the continuous expansion of online platforms, challenges about user safety, content integrity, and the prevention of malicious activities intensify. AI-driven solutions are pivotal in addressing these threats by proactively identifying and mitigating emerging risks and cultivating a secure online environment. This is why, in the domain of Trust and Safety, accurate and relevant annotated data is crucial for effective machine learning, directly shaping the performance of AI models.
Below are specific examples illustrating the crucial role of data annotation in the T&S endeavour, outlining the primary processes it supports:
- Content Moderation for Enhanced Safety: By meticulously labelling data, automated moderation tools can accurately assess and filter user-generated content, helping identify and remove materials that may be inappropriate, harmful, or violate community guidelines.
- Mitigating Emerging Cyber Risks: Data annotation helps efficiently address evolving cyber threats, such as phishing attempts, malware distribution, and data breaches. It enables the proactive identification and prevention of cybersecurity challenges by helping AI models recognise patterns.
- Reinforced User Authentication: Annotation detects spam, fraud, and malicious activity, specifically contributing to user authentication. This improves identity verification, reinforces security measures, and adds an extra layer of protection, safeguarding user data and interactions.
How does the annotation process work?
Data annotation typically encompasses several steps engaging skilled talents and relevant technological solutions.
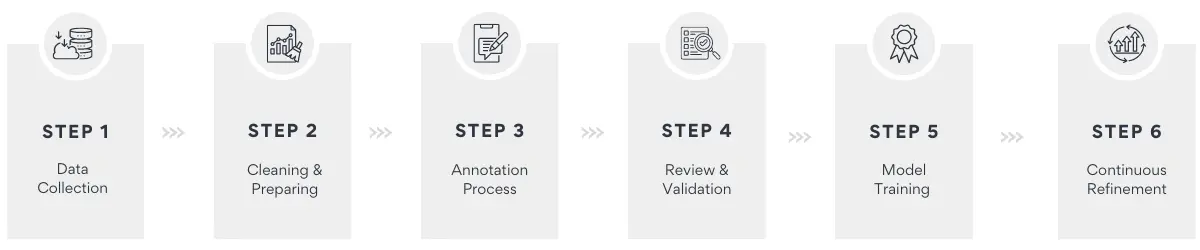
The annotation journey starts with the crucial data collection phase. The scope of raw data varies based on the specific task and goals of the machine learning model under development. Examples may include textual elements such as sentences, paragraphs, documents in different languages, numerical data, image datasets, voice recordings, or videos. Before annotation, the collected data undergoes a cleaning and preprocessing phase to ensure its quality and relevance. In the next phase, well-prepared data is annotated. One or more tags are assigned to each piece of record, providing precise information about their characteristics or features. Annotation can be achieved through manual efforts, where human annotators review and label the data, ensuring a nuanced understanding of its attributes. Alternatively, it can be supported by software tools specifically designed for efficient and accurate annotation operation.
Accordingly, ensuring the assigned tags’ accuracy and quality is critical. Such initiative involves reviewing and validating the annotations to guarantee that they align with the intended context and are specific enough to guide the model effectively. In the final stage, the annotated data trains the machine learning model. Throughout this process, algorithms grasp trends and correlations between the labelled data and desired outcomes. Importantly, this should be an ongoing process, necessitating continuous refinement and validation of annotations to ensure optimal performance over time.
The decision between manual and automated methods relies on factors like data complexity and the size of the annotation task. Human annotators are great for interpreting complex or subjective data, using their expertise and judgment to label accurately. For large datasets or projects that can be automated, software tools are used to improve efficiency and maintain consistency in labelling. Typical software used for annotation usually includes data collection tools, data cleaning and preprocessing solutions, annotation software, machine learning-assisted labelling tools, data preprocessing algorithms, and collaboration platforms that facilitate teamwork among annotators.
What are the common types of data annotation?
Data annotation is becoming more diverse, involving various labelling processes for different data types. The expansion of data categories and formats is expected to continue as the demand for such services grows.
Nowadays, the most common data annotation types include:
- Text Annotation: Adding labels to text documents or specific parts essential for training chatbots and other natural language processing algorithms.
- Semantic Annotation: Labelling concepts like “people” or “places” in text to improve machine learning models crucial for chatbots and search relevance.
- Image Annotation: Making machines recognise objects in images using bounding boxes.
- Video Annotation: Systematical labelling or marking of various elements within a video frame-by-frame basis.
- Audio Classification: Sorting audio samples into categories like speech or music, commonly used for training virtual assistants.
- Text Categorisation: Assigning categories to sentences or paragraphs in a document important for applications, making it easier to retrieve, analyse, and extract valuable insights from textual data.
- Entity Annotation: Helping machines understand unstructured sentences using techniques like Named Entity Recognition (NER).
- Intent Extraction: Labelling phrases or sentences with intent, a key tool for training chatbot algorithms.
- Phrase Chunking: Tagging parts of speech for grammatical definitions, essential for natural language processing (NLP).

What is the difference between annotation, tagging and labelling?
Data annotation is a comprehensive process that includes tagging and labelling as specific methods within its framework. The nuances between the three concepts are context-dependent, and their relationship highlights the multifaceted nature of the overall undertaking.
Annotation entails adding metadata, labels, or tags to raw data to optimise machine learning algorithms. It can be implemented for diverse data types, including text, images, videos, and audio. Tagging is a specific form of data annotation where descriptive keywords or labels are assigned to individual pieces of data. It is commonly used in various contexts, such as social media, content organisation, and information retrieval. Labelling, another facet of annotation, focuses on assigning categorical or class labels to elements within a given dataset. It is pivotal for training machine learning models to perceive patterns and make forecasts based on labelled examples.
What are the major benefits and challenges of data annotation?
The benefits of accurate data annotation are significant from both technical and business perspectives. Nevertheless, the process is fraught with several challenges, and overcoming them is a cornerstone for the success of the entire initiative.
Outstanding data annotation helps guarantee control over the output, aligning results with desired objectives and instilling user confidence. The insights derived this way are more reliable and trustworthy, significantly enhancing decision-making, boosting task performance, strengthening competitive positioning, and fueling organisational innovation and growth. Therefore, making it suitable is worth investing time, effort, and money, ensuring optimal results and addressing challenges in the dynamic landscape of data annotation. These refer to key hurdles, such as:
- The Need for a Substantial Volume of Data: To ensure effective annotation for AI models, having a substantial amount of relevant, high-quality and legal data is necessary, and its volume always depends on the project requirements. This can be achieved by sourcing data strategically, using in-house data and public databases, collaborating with data providers or leveraging crowdsourcing platforms to collect labelled data from a diverse group of contributors.
- Annotation Speed: This is another obstacle that can be addressed by investing in automation tools for streamlined processes, especially when relying to some extent or solely on human annotators. In such cases, technology can enhance efficiency and accelerate annotation performance.
- Data Quality and Consistency: Consistency in data quality is an issue, as variations can impact the effectiveness of machine learning models. It can be maintained through ongoing assessments of the tools and processes employed in the annotation workflow.
- Secure Environment: Creating a safe environment is obligatory when dealing with data. It involves implementing robust security measures to prevent data breaches and safeguard sensitive information. The more sensitive data is handled, the higher the importance of stringent security protocols. Implementing encryption, access controls, and regular security audits are integral to maintaining a secure data annotation ecosystem.
- Mitigating Human Bias: This involves addressing biases introduced by annotators influenced by personal experiences, cultures, and perspectives. Regular training and monitoring help minimise subjective interpretations in datasets, promoting objectivity in machine learning applications.
What are the best practices for data annotation?
Following best practices for data annotation is a chance to succeed in managing AI-driven projects. Below are a few suggestions and tips on how to build an efficient annotation best practice strategy.
Conclusion
In summary, with all the benefits and challenges to overcome, data annotation is an impactful tool for elevating the performance of machine learning models. It helps unlock the full potential of artificial intelligence, elevating analytical capabilities across diverse industries, including social media, gaming, travel and hospitality, e-commerce, finance and various autonomous systems. As the demand for data annotation increases due to its critical role in model training, the field is poised for further development, driven by technological advancements and collaborative efforts, making it a key player in the ongoing evolution of artificial intelligence.



